
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

В данной статье подробно рассматривается частный случай для получения картинок с определенного сайта и возможно вам будет достаточно базового функционала расширения KellyC Image Downloader
Если же сайт по умолчанию не поддерживается расширением и расширение собирает только превьюшки которые есть на странице без возможности скачать оригиналы (оригинал находится в дочернем документе), то в таком случае можно попробовать использовать функцию "Загрузить доп. данные" расширения Image Downloader.
В качестве примера работы с функцией и получаения оригиналов с ее помощью буду использовать свой сайт Catface.RU

основной раздел сайта с лентой новостей. картинки - превью макс. 940 пикс. в ширину
catface.ru по умолчанию поддерживается расширением, и на нем нет необходимости прибегать к загрузке дочерних документов, но думаю использовать чужой сайт в качестве примера было бы неправильно, так что учитывайте условности.
Так при открытии к примеру страницы https://catface.ru/last/ видно, что картинки превью имеют url вида
Код JavaScript:
catface.ru/userfiles/media/previews/940/width/opt_udata_1601920573_idkluwql.webp
Мы может подобрать регулярное выражение которое будет фильтровать картинки по этому формату ссылки
Регулярное выражение для такой ссылки
Код JavaScript:
userfiles/media/previews/[0-9]+/width/opt_udata_[0-9]+_[a-zA-Z]+.[a-zA-Z]+
Оригинал находится на другой странице и имеет url вида
Код JavaScript:
catface.ru/get/1222
Регулярное выражение для такой ссылки
Код JavaScript:
get/[0-9]+
Теперь когда мы определились с параметрами фильтрации можно получить список оригиналов таким образом :
1. Формируем список картинок (ходим по страницам сайта в режиме записи)
2. Выделяем через доп. фильтры по совпадению url все превьюшки регуляркой
Код JavaScript:
userfiles/media/previews/[0-9]+/width/opt_udata_[0-9]+_[a-zA-Z]+.[a-zA-Z]+
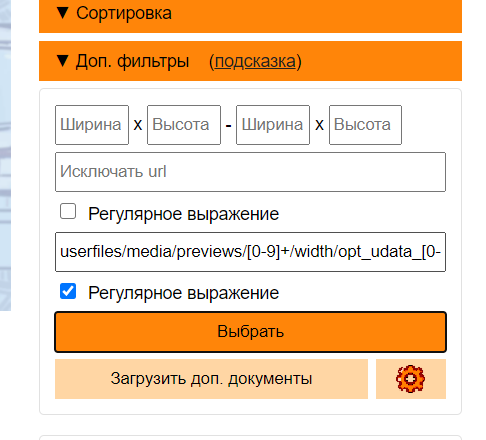
Галочка на "Регулярное выражение", иначе будет просто поиск по совпадению в строке url
Если отфильтрованные картинки содержат ссылку на документ ведущий на страницу с оригиналом картинки, значит все ок и можно продолжать настройку дальше. Если же документ не тот или отсутствует, то потребуется программная реализация фильтра на javascript. Подробная документация о javascript фильтрах для расширения описана здесь (требуются знания JavaScript)

При наведении на отфильтрованную картинку появляется ссылка на страницу с оригиналом, а значит можно загрузить дочерний документ и вытянуть из него оригинал картинки
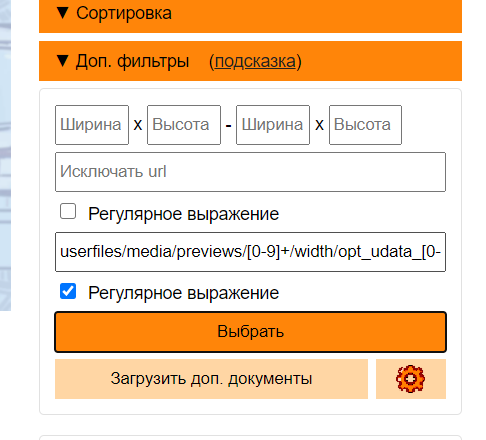
3. Открываем настройки загрузки доп. данных и вводим совпадение url
Код JavaScript:
get/[0-9]+

доп. настройки. Галочка на "Регулярное выражение", иначе будет просто поиск по совпадению в строке url
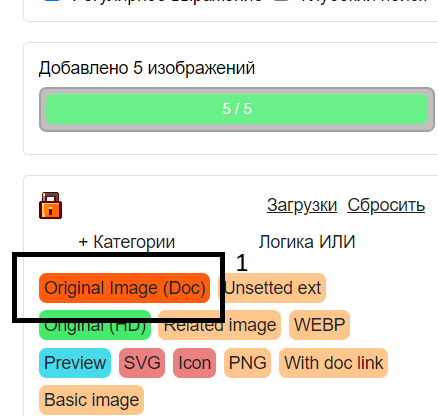
4. Кликаем на "Загрузить доп. данные"
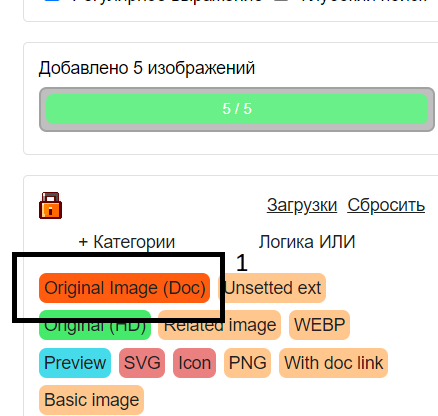
Если загрузка дочерних документов прошла удачно, найденные в них картинки будут сгруппированы в группу "Original Image (Doc)". Дальше их можно скачать обычным способом через кнопку "Загрузки".
Картинки Рисунок №1 by nradiowave, Как пакетно скачать оригиналы картинок, #расширение #chrome #image_downloader #download_manager #скачать_картинки, Рисунок №2 by nradiowave, Как пакетно скачать оригиналы картинок, #расширение #chrome #image_downloader #download_manager #скачать_картинки, Рисунок №3 by nradiowave, Как пакетно скачать оригиналы картинок, #расширение #chrome #image_downloader #download_manager #скачать_картинки, Рисунок №4 by nradiowave, Как пакетно скачать оригиналы картинок, #расширение #chrome #image_downloader #download_manager #скачать_картинки, Рисунок №5 by nradiowave, Как пакетно скачать оригиналы картинок, #расширение #chrome #image_downloader #download_manager #скачать_картинки, Рисунок №6 by nradiowave, Как пакетно скачать оригиналы картинок, #расширение #chrome #image_downloader #download_manager #скачать_картинки